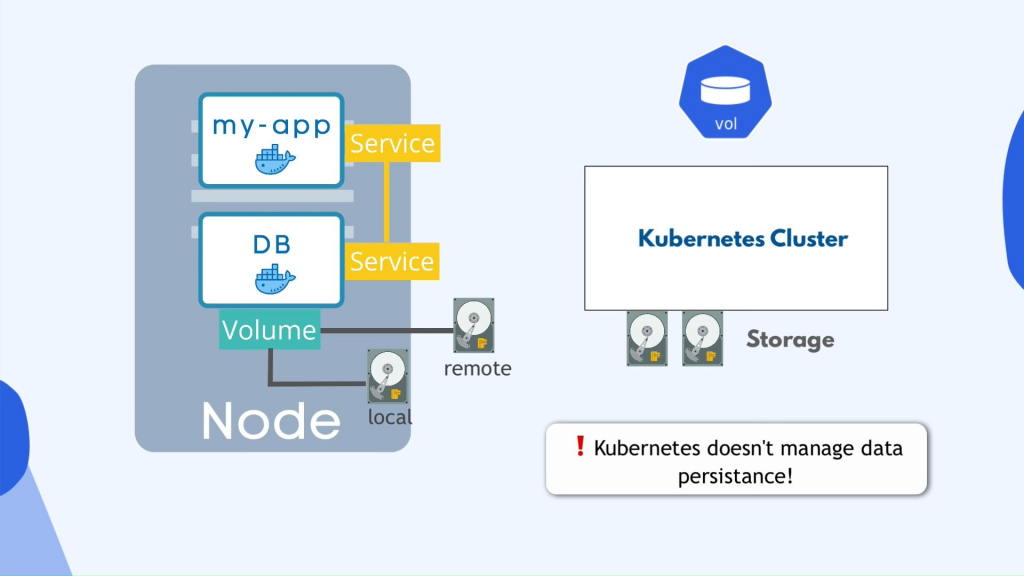
一个非常重要的概念,即数据存储data storage及其在 kubernetes 中的工作方式,所以我们有我们的应用程序使用的这个数据库 pod,它有一些数据,或者它生成一些数据如果数据库容器或 pod 重新启动,你现在看到的这个设置数据将会消失,这显然是有问题和不方便的因为你希望你的数据库数据或日志数据能够长期可靠地持久化,以及你在 kubernetes 中可以做到的方式正在使用 kubernetes 的另一个组件,称为卷volumes它的工作原理是它基本上将硬盘驱动器上的物理存储附加到您的 pod,并且该存储可以在本地机器上,意味着在pod 运行的同一服务器节点上,或者它 可能在远程存储上,这意味着在kubernetes 集群之外,它可能是一个云存储,或者它可能是您自己的前提存储,它不是kubernetes 集群的一部分,所以您只有一个外部引用,所以现在当数据库 pod 或 容器重新启动所有数据都将保留在那里了解kubernetes集群及其所有组件和存储之间的区别很重要,无论它是本地存储还是远程存储kubernetes 集群因为重点是kubernetes 集群明确不管理任何数据持久性,这意味着您作为 kubernetes 用户或管理员负责备份数据复制和管理它并确保它保存在适当的硬件上等因为它没有处理 kubernetes
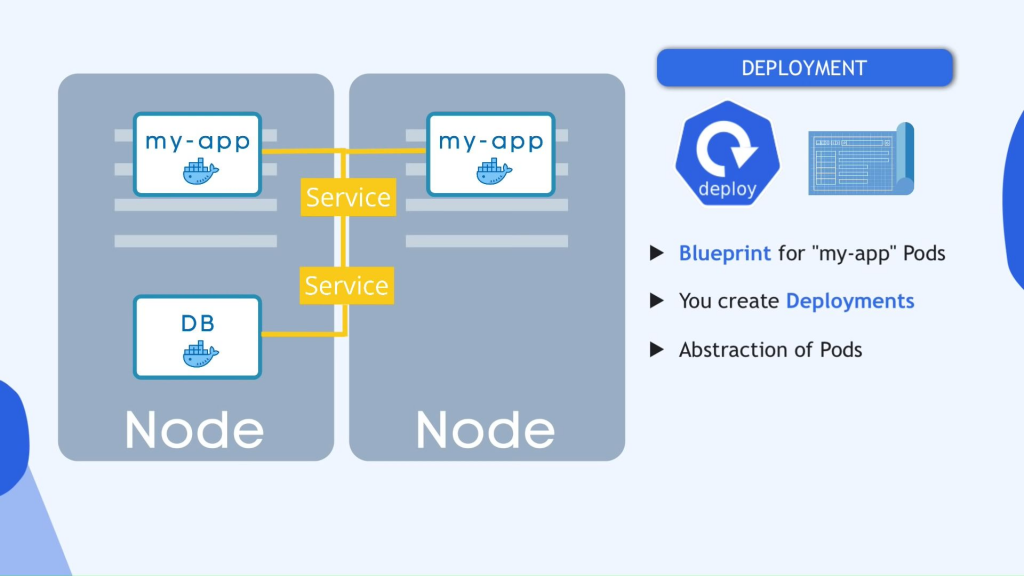
现在让我们看看一切都在完美运行并且用户现在可以使用此设置通过浏览器访问我们的应用程序如果我的应用程序 pod 正确崩溃或者我必须重新启动 pod 会发生什么,因为我构建了一个新容器基本上我会有一个停机时间,用户可以访问我的应用程序 如果它发生在生产中,这显然是一件非常糟糕的事情,这正是分布式 系统和容器的优势,而不是仅仅依赖一个 应用程序部分和一个数据库部分等等我们在多个服务器上复制所有内容,因此我们将有另一个节点,我们的应用程序的副本或克隆将在该节点上运行,该节点也将连接到该服务,因此请记住之前我们说过该服务就像一个带有 dns 名称的持久静态 ip 地址这样您就不必在pod 死机时不断调整终点,但服务也是一个负载均衡器,这意味着该服务实际上会捕获请求并将其转发到最不忙的部分,因此它具有这两种功能但是为了创建我的应用程序 pod 的第二个副本,您不会创建第二部分,而是您将为我的应用程序 pod 定义一个蓝图,并指定您想要运行的那个 pod 的副本数量和该组件 或者该蓝图blueprint称为部署deployment,它是kubernetes 的另一个组件,在实践中,您不会使用Pod,或者您不会创建 Pod,您将创建部署,因为您可以在其中指定多少个副本,也可以扩展或扩展 减少你需要的 pot 副本的数量,所以对于 pot,我们说pot 是容器之上的抽象层,部署是 pot 之上的另一个抽象层,这使得与 pod 交互更方便复制它们并做一些事情 其他
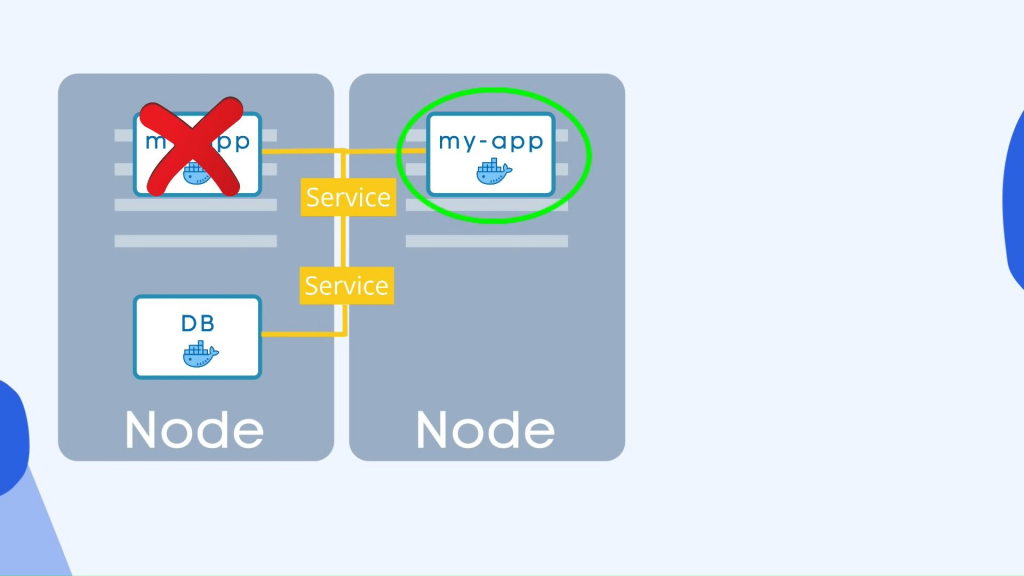
配置所以在实践中你主要使用部署而不是 pod 所以现在如果你的应用程序 pod 的一个副本会死掉,服务会将请求转发给另一个,这样用户仍然可以访问你的应用程序
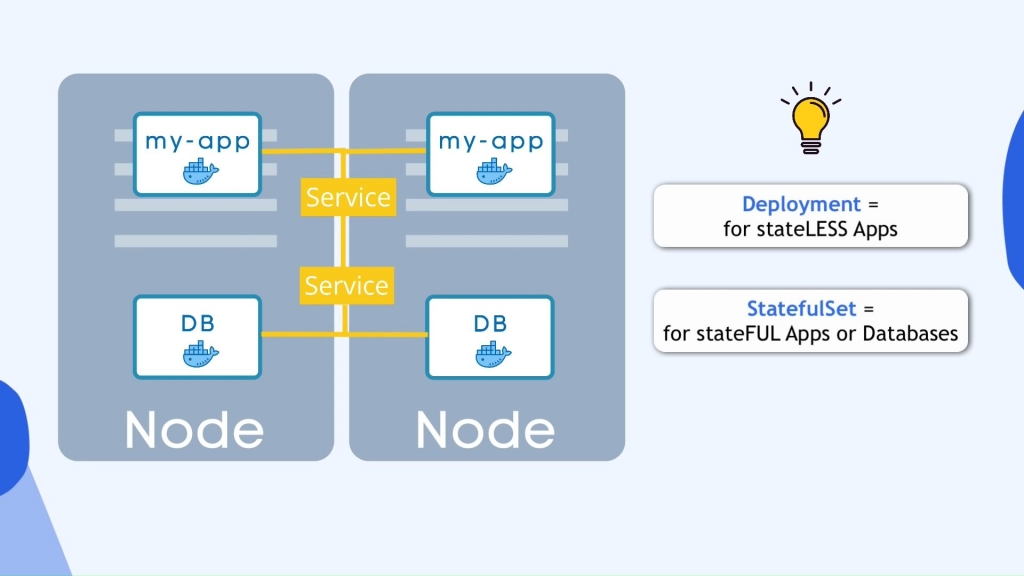
所以现在你 我可能想知道数据库 pod 怎么样,因为如果数据库部分死了,你的应用程序也将无法访问,所以我们也需要一个数据库副本,但是我们不能使用部署复制数据库,原因是数据库有 一种状态,即它的数据,这意味着如果我们有数据库的克隆或副本,它们都需要访问相同的共享数据存储,并且您需要某种机制来管理当前正在写入该存储或哪些 Pod 的部分 正在从存储中读取以避免数据不一致,并且除了复制功能之外,该机制由另一个名为 statefulset 的 kubernetes 组件提供,因此该组件专门用于数据库等应用程序,因此 mysql mongodbelasticsearch 或任何其他有状态应用程序或数据库应该是 使用有状态集而不是部署创建这是一个非常重要的区别,有状态说就像部署会负责复制pot并将它们放大或缩小但确保数据库读写同步以便不提供数据库不一致 但是我必须在这里提到,在 kubernetes 集群中使用有状态集部署数据库应用程序
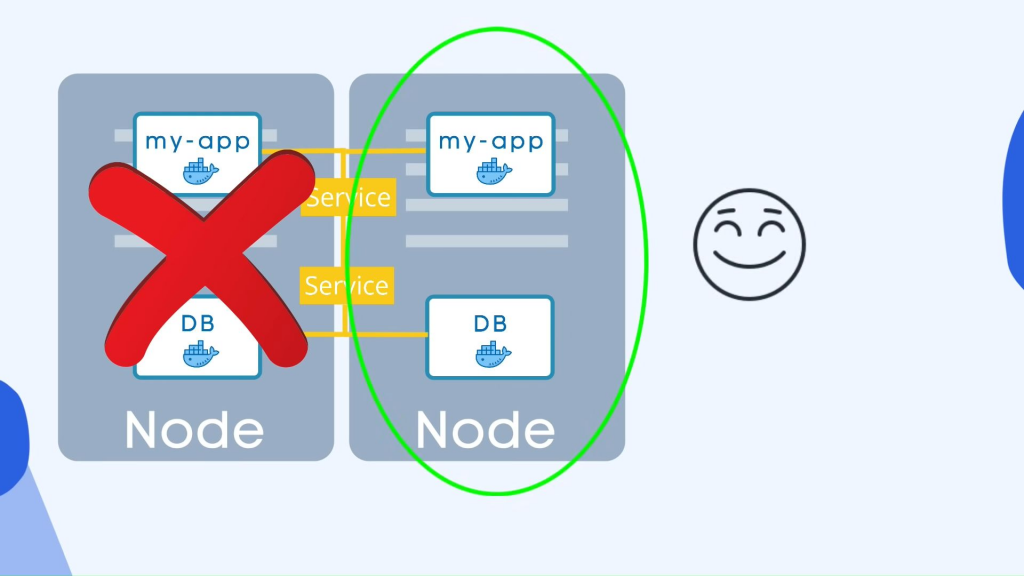
可能有点乏味,因此它肯定比在没有所有这些挑战的情况下进行部署更困难,这就是为什么在 kubernetes 集群之外托管数据库应用程序也是一种常见的做法kubernetes集群,只有部署或无状态应用程序可以在kubernetes 集群内部毫无问题地复制和扩展,并与外部数据库通信,所以现在我们有我的应用程序 pod 的两个副本和数据库的两个副本,它们是 两者都是负载平衡的,我们的设置更加健壮,这意味着现在即使整个节点服务器实际上重新启动或崩溃并且没有任何东西可以在其上运行,我们仍然会有第二个节点在其上运行应用程序和数据库 pod,应用程序将 在重新创建这两个副本之前,用户仍然可以访问,这样您就可以避免停机